Por Marc Alcantara.
Em 25/05/2017 no site Profissionais TI.
3) Aplicação de exemplo
Como suporte a este artigo, temos nos servidores da classeasoft um exemplo simples de aplicação prática destes conceitos. Se trata de um sistema gestor de chamados, o mesmo que JIRA, Mantis, etc. O problema proposto aqui para que se resolva mediante estas tecnologias é que o workflow seja totalmente flexível. É dizer que o usuário pode definir o circuito de estados de chamados da forma que ele quiser. Como, por exemplo: Aberto, proposto, em desenvolvimento, em teste e solucionado. Permitindo configurar todo o fluxo e, se necessário, voltar a etapas prévias ou saltar estados.
No momento em que desenvolvi este sistema vivia na Argentina, por esta razão podem notar alguns comentários em Espanhol, tentarei explica-los todos aqui, mas caso tenham alguma dúvida podem me escrever perguntando.
- Endereço na WEB da aplicação: http://www.prototipo.classeasoft.com
- Github: https://github.com/marcola1910/item
- Código fonte em pasta zip: https://www.dropbox.com/s/kfgcwaadq6kvufa/item.zip
Acesso ao Administrador do site:
- user: adm@nihil.com
- pwd: 1
3.1) Explicando o Modelo de Domínio
Diferentemente do padrão Table Module, criamos um diagrama de modelo de domínio para representar a aplicação ao invés de iniciar com um diagrama de entidades relação de base de dados. Partindo do principio de substantivos e verbos podemos criar classes e traçar as relações entre elas.
Abaixo podemos conferir o diagrama de domínio da aplicação.
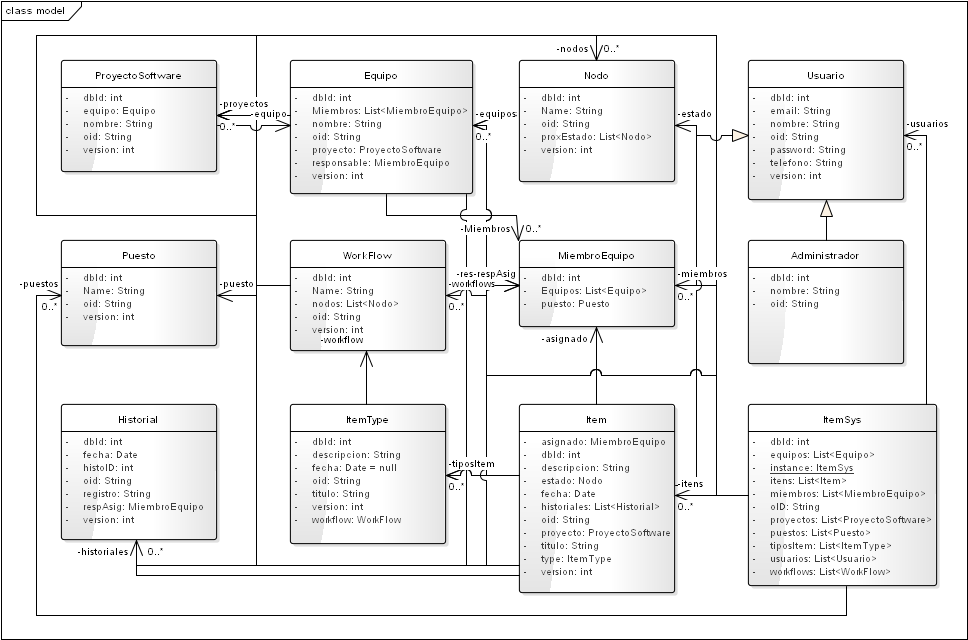
Aqui estão todos os elementos necessários para a solução com suas representações e relações, porém, há um elemento a mais que representa o sistema em si mesmo. Note a classe ItemSys que contem como atributo listas de outros elementos dos sistemas, o que seriam os dados mestres em outras metodologias. Isso se deve ao uso de um padrão de desenho de arquitetura chamado RootObject. Que podemos entrar em mais detalhes sobre ele explicando seus benefícios e suas desvantagens.
A principal dificuldade que eu vi na aplicação do Domain Model por parte de desenvolvedores que vinham usando outros padrões, é a indefinição de como usar um modelo de objetos onde os dados são representados em instancias de classes ao invés de linhas de uma tabela. Tecnicamente falando seria o impasse de tentar usar o Domain Model e Data Row gateway que é algo que não funciona bem devido ao que chamamos diferença de impedância.
A solução para esse caso seria ou armazenar os objetos tal qual estão na memoria em representações de grafos no disco, ou simplesmente mapear a relação entre os objetos e os registros no banco de dados. Surge ai então o padrão Data Mapper que dá origem à ferramentas de ORM como o Hibernate que lida com este problema.
Porém como já sabemos, quando criamos uma nova solução também podemos criar novos problemas. E ao utilizar o DataMapper temos que pensar em como controlar os limites de transação das operações. Por exemplo: Interatuando entre diferentes objetos em um processo notamos que ocorre uma exceção esperada ou inesperada, como saberemos o ponto que devemos fazer rollback e reverter as modificações de dados ocorridas até então?
No caso de estar utilizando o Transaction Script ou até mesmo o Table Module, seria muito mais fácil porque a execução estaria em blocos de códigos procedurais, no caso do Domain Model podemos utilizar o RootObject para isso. O Root object é o objeto raiz que deve representar o sistema em si, e raiz porque ele é também a raiz da representação de um grafo.
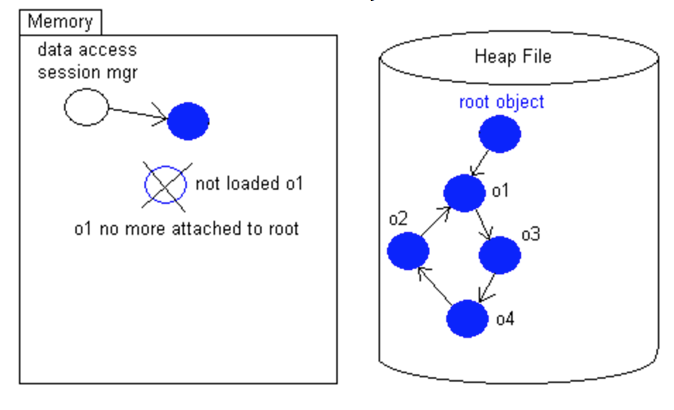
O padrão Root Object será a base de outra técnica que posteriormente irei mostrar chamada de persistência por alcance. Que basicamente controla olimite de transação tendo em conta os objetos afetados na estrutura do grafo.

3.2) Explicando a estratégia para tornar a arquitetura flexível para cloud computing.
Retomando ao tema original, nosso objetivo é tornar a arquitetura flexível o suficiente para escalar em outros servidores, outros repositórios de dados e se integre a diferentes serviços ou até mesmo prover serviços para que aplicações mobile a consumam, que atualmente é o que tende a ocorrer. Com o modulo de persistência resolvido com o root object falta então abstrair a camada de dados e de serviços. Abaixo segue um diagrama de pacotes que busca representar toda a estrutura.

Note que a aplicação web Wicket, representada pela classe mais acima, somente tem acesso aos pacotes de repositórios, serviços e DTOs. Essa foi a forma de separar as camadas e permitir escalar em vários tipos de serviços e repositórios de dados. Claro que somente a separação de pacotes não nos dá esta flexibilidade, por isso criamos a classe RepositoryLocator e ServiceLocator. Estes 2 na verdade nada mais são que classes que armazenam as instancias de serviços e repositórios, permitindo também a injeção de dependência.
Injeção de dependências (Inversão de controle)
Esta técnica permite injetar de forma dinâmica um serviço ou um repositório de dados sem impactar no funcionamento do cliente ou do modelo. Esta aplicação de exemplo trabalha com base de dados MySQL e com serviços representados por uma classe. Caso queira instalar esta mesma estrutura em um outro ambiente onde usa serviços SOA, CORBA ou etc, podemos adaptar o sistema e injeta-lo mediante a uma configuração XML do Spring. O mesmo para o repositório de dados, onde podemos sem muito impacto usar múltiplos bancos de dados independente da tecnologia sem impactar no modelo. Pois o modelo como podem ver no diagrama esta na parte mais abaixo somente sendo consumida pela implementação de repositório ( que neste caso o Hibernate) e serviços. Um caso clássico é escalar múltiplos banco de dados para uma mesma aplicação por meio do cloud computing sendo que o esforço de código seria mais que nada adaptar um novo modulo e injeta-lo no locator. Assim como também outros serviços integráveis. O segredo na realidade é que o modelo e o cliente estão devidamente separadas por uma camada de abstração.
No nosso exemplo, no código vocês podem conferir a seguinte configuração no arquivo de configuração do Spring que direciona as injeções de dependência em detalhe.

Esse arquivo define que um bean criado pelo método getInstance() tenha como valores de seus atributos as seguintes instancias de classes assim como definida em cada propriedade.
Logo podemos acessar a estes serviços pela camada de apresentação.

Vejam que o método adicionar estado pelo serviço que é chamado pela camada de apresentação através do ServiceLocator e logo se recebe um Set de dados como resposta classificado como DTO( data transfer objects) que são nada mais que os valores de objetos de domínios que chegam até a camada de apresentação.
A mesma coisa seria uma aplicação mobile que poderia consumir um serviço como esse, porém através de um WEB service. Através desta técnica seria mais transparente a alteração para escalar o acesso ao modelo de domínio.
Proxy Pattern
Este padrão por essência, trabalha com a representação de um objeto sem interagir diretamente com ele. Para o nosso caso que estamos buscando soluções para abstrair a camada de dados nos ajuda. A equipe do Hibernate notou a utilidade deste padrão e aplicou no seu produto permitindo o uso do LazyLoad, que nada mais é que trazer os dados solicitados de um determinado conjunto de classes sem ter que trazer necessariamente todas as instancias de todas as propriedades. No arquivo applicationContext.xml que esta na pasta WEB-INF, pode-se notar as configurações do hibernate para o mapeio das classes do domínio com as tabelas. O valor padrão do atributo lazy é verdadeiro portanto não é necessária nenhuma ação direta para este caso.

Decorator Pattern
O Padrão decorator permite acrescentar comportamentos pre definidos a um objetos de forma dinâmica. Outro padrão do livro do Gang of Four que foi parar nos principais frameworks de desenvolvimento de software, como neste caso o Spring.
Por meio do reflection o Spring instancia os objetos que configuramos e armazena onde queremos, que no nosso caso é o ServiceLocator. E a equipe do Spring foi inteligente o suficiente para perceber que se “decorar” uma operação dentro de um serviço com um gestor de transação, pode-se então trabalhar com persistência por alcance, como havia mencionado na secção de root object. Porque isso conseguimos quando decoramos os comandos de transação( tx.begin(), tx.commit() tx.rollback() e etc) injetando eles sobre um bloco de código. Essa tecnica será melhor descrita no item a seguir.
Unit of Work com Spring
Sendo que, todos os objetos do modelos estão abaixo do root object. Se qualquer objeto deste grafo for modificado, o hibernate marca o root object para alteração assim como todos os objetos subsequentes. Sendo assim, aliando este root object com o gestor de transação do Spring e hibernate, podemos fazer o que chamamos persistência por alcance com características ACID.
Basicamente dentro do arquivo de contexto do Spring configuramos o mapeio.

Logo configuraríamos o gestor de transações do Spring para os nosso serviços.

O fato de configurar Propagation_Required_NEW como atributo no gestor de transação permite o uso do bloco de código na transação e sempre pede para que uma nova transação seja criada.
Utilizamos o nível de isolamento padrão do banco de dados e temos uma arquitetura preparada para receber nosso modelo de domínio inteiramente representado em objetos, colocando no nível de controle de transação no momento de chamar o serviço seja pela camada de apresentação com o wicket ou qualquer outra fonte que esteja consumindo o nosso service locator.
Conclusão
Podemos notar que na literatura da engenharia de software há soluções para se trabalhar com Domain Model, mais comumente usado hoje como DDD (Domain Driven Design). Que permite reduzir a complexidade do esforço de modificação a longo prazo e a ajuda do Ubiquitous Language na comunicação da equipe impactanto positivamente em todas as disciplinas da engenharia de software como o teste por exemplo. O sistema publicado no link prototipo.classeasoft.com é uma prova cabal que SIM! É possível trabalhar com esses princípios e o único impacto de performance nisso seria o dos próprios joins nas queries do motor de base de dados. Ao contrário dos que dizem que DDD seja lento, com os repositórios abstraídos pode até mesmo trabalhar com alguns casos de uso na memoria e ao final persistir nos repositórios RDBMS ou até mesmo usar nesta camada outros frameworks de dados mais orientados a NoSQL como datanucleos ou até mesmo Neo4J ou DB4o e Versant que são bases de objetos.
Qualquer dúvida, sugestão ou crítica, por favor, deixe seu comentário abaixo!
Bibliografia
- Gamma, Eric, Helm, Richard, Johnson, Ralph, Vlissides, John. Design patterns, elements of reusable object-oriented software. Addison- Wesley. 1995;
- Craig Larman, 2007, “Utilizando UML e Padrões”, 3ª ed., Bookman;
- Eric Evans, 2010, “Atacando as complexidades no coração do software”, Alta Books
- PEZZÈ, M.; YOUNG, M.; Teste e Análise de Software. Porto Alegre: Bookman, 2008;
- COCKBURN, A.; Escrevendo Casos de Uso Eficazes – Um Guia para Desenvolvedores de Software. São Paulo: Bookman; 2005 ;
- Fowler, Martin. Patterns of enterprise application architecture. Addison – Wesley. 2002;
- FOWLER, M. UML Distilled: A Brief Guide to the Standard Object Modeling Language, 3rd Edition, Addison-Wesley, 2003;
- Persistencia orientada a Objetos – Mg Javier Bazzocco – Editora UNLP – La Plata 2010;
Online
- Hibernate. <http://www.hibernate.org>
- ODBMS. < http://www.odbms.org>
- Db4o. <http://www.db4o.com>
- Spring framework. <http://www.springsource.org>
- Padrões na nuvem <http://classeasoft.com/utilizando-padroes-arquiteturas-avancadas-na-nuvem-java/>
- Versant. <http://www.versant.com>
- Wicket. <http://wicket.apache.org >
- AWS <http://aws.amazon.com>
Nenhum comentário:
Postar um comentário