Por Regina Cantele em 28/11/2017 no site iMasters
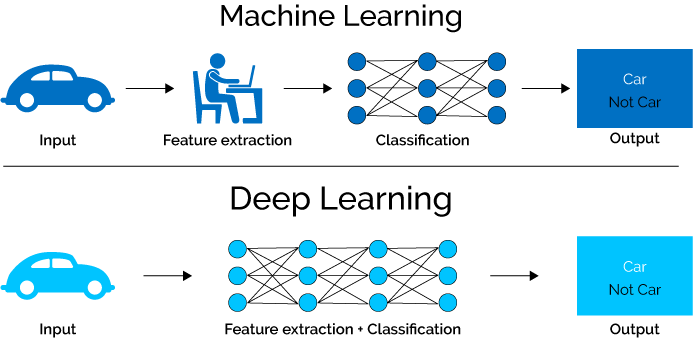
Machine Learning (ML) é um tópico central na Inteligência Artificial (IA). Atualmente, seu uso em situações abordadas no Big Data é muito conhecido como nos sistemas de recomendações ou nos chatbots, entre outros. No entanto, a complexidade de seu uso não está somente nos diferentes tipos de dados e situações, mas também na existência de diferentes métodos que podem ser usados.
O cientista de dados experiente pode ter conhecimento dos métodos e suas aplicações, mas para iniciantes pode não ser óbvio onde encontrar essa informação. Weka e RapidMiner são ferramentas criadas para facilitar o acesso aos métodos de ML e permitem aos não especialistas a usarem o ML facilmente.
No entanto, apenas o acesso a uma grande quantidade de métodos de aprendizagem de máquinas sem o conhecimento de como usá-lo resolve uma parte dos problemas.
Um destes métodos é o sistema baseado em regras, ou seja, um tipo de modelo que procura representar o modo de raciocínio e o conhecimento aplicado por especialistas na resolução de problemas no âmbito de algum contexto. Para isto, utiliza regras explícitas para expressar o conhecimento do domínio de um problema e permite, através da confrontação do conhecimento existente com fatos conhecidos sobre um determinado problema, inferir novos fatos.
Possui dois componentes principais: o conhecimento dado em forma de regras e fatos e o mecanismo de raciocínio (reasoner engine).
O mecanismo de raciocínio é uma ferramenta que, a partir de um conjunto de regras e fatos, pode inferir novos fatos seguindo algum tipo de formalismo de lógica, como lógica de primeira ordem (FOL) ou lógica de descrições (DL). Os dados precisam ser representados no formalismo com o qual o mecanismo funciona.
O conhecimento de regras e fatos pode ser expresso em uma ontologia – uma descrição formal explícita de conceitos em um domínio de discurso, propriedades de cada conceito descrevendo várias funcionalidades e atributos de conceitos, e restrições das propriedades.
Formalmente, pode-se definir uma ontologia como uma tupla (C, I, R, F, A):
- C é um conjunto não vazio de conceitos – abstrações usadas para descrever os objetos do mundo;
- I é um conjunto de indivíduos e suas relações – os objetos atuais do mundo, também conhecidos como instâncias dos conceitos, facts ou claims;
- R é o conjunto de relações definidas em C. Representam as interações entre os conceitos do domínio, independentes de sua utilização e também conhecido como conjunto de ações e heurísticas. R é particionado em dois subconjuntos H e N. H é um conjunto de todas afirmativas na qual a relação é uma relação taxonômica (expressa uma hierarquia) e N é um conjunto de todas afirmativas não taxonômicas (expressa uma ação);
- F é o conjunto de funções definidas em C e seu retorno é um conceito;
- A é o conjunto de axiomas – predicados da lógica de primeira ordem que restringem o significado dos conceitos, relações e funções; o resultado é sempre uma sentença verdadeira.
Para ontologias, seu objetivo principal é expressar um significado lido, automaticamente, para suportar o mecanismo de raciocínio automatizado acurado.
Como as ontologias são teorias formais que descrevem um domínio, elas requerem uma linguagem lógica para representá-las. A escolha de uma linguagem ou outra se dará pelo seu poder de expressividade, existência de ferramentas para sua edição (ex.: Protégé), banco de dados (ex.: Stardog), necessidade de mecanismos de raciocínio e pela existência de ferramentas para anotação dos recursos, entre outros fatores.
Algumas ferramentas com mecanismos de raciocínio são: Drools, JESS (Java Expert System Shell), Apache Jena e JEOPS (Java Embedded Object Production System), entre outros.
O consórcio W3C propôs uma arquitetura para padronização de protocolos e linguagens para compartilhar e reutilizar informações na Web como RDF (Resource Description Framework), SPARQL, OWL (Web Ontology Language) e RIF (Rule Interchange Format). Esta arquitetura define as tecnologias necessárias para que os conteúdos dos recursos Web possam ser compreendidos pelas máquinas e sua contribuição é prover um conjunto de padrões – linguagens, sintaxe comum, métodos etc.
Aplicações podem utilizar ontologias existentes ou construí-las. No primeiro caso, tem-se exemplos para IoT – Semantic Sensor Network Ontology (SSN ou SSNO), carros autônomos – Generic Automotive Ontology (GAO), finanças – Financial Ontology (FIBO) e e-commerce – GoodRelations.
No segundo caso, um exemplo é a aplicação Safety Check, usada para identificar pessoas que possam ser afetadas devido a desastres naturais, como: terremotos, inundações, secas, tempestades, ciclones, furacões, deslizamentos de terra, erupções vulcânicas, surtos de doenças etc.; e para fornecer informações importantes sobre a crise, como qual área é afetada, qual é a extensão do desastre, quando é seguro voltar e onde encontrar abrigo. Usa alertas públicos do Google para obter essas informações antes, durante e após um desastre. Com as atualizações em tempo real sobre o que está acontecendo, o aplicativo é uma maneira pela qual a Web pode procurar por pessoas.
Esta aplicação utiliza informações de vários domínios e fontes, como pessoas, cidades, coordenadas, terremotos e alertas climáticos. Foram realizadas diferentes abordagens para extrair dados para cada conjunto de dados:
- Os dados das pessoas foram coletados usando as API gráficas do Facebook. Foi desenvolvido um programa de cliente que usa tokens de acesso, para obter informações de amigos e familiares;
- Para coletar informações sobre grandes cidades como latitude / longitude, área, população etc., foram implementados rastreadores web que reuniram dados no formato CSV;
- Para coletar informações sobre terremotos e clima, os alertas públicos do Google.
Exemplos de duas regras desenvolvidas e implementadas na aplicação transcritas aqui:
Regra 1: associar pessoas com suas regiões com base no atributo “locationName”. O conhecimento inferido fornece as coordenadas de uma pessoa:
Regra 2: identificar todas as pessoas que podem ter sido afetadas devido a um terremoto:
Ao definir as regras, o mecanismo de raciocínio infere às pessoas afetadas dados sobre o terremoto, como a magnitude, o epicentro e as coordenadas das pessoas presentes no local. A distância radial sobre os efeitos do terremoto foi estimada usando McCue Radius of Perception Calculator. A aplicação utilizou Apache Jena com consultas SPARQL.
De forma mais abrangente, todas as situações, quer envolvam interpretação de dados como comportamento social ou ações da IoT, podem ser expressas em um sistema baseado em regras mediante uma ontologia formalmente definida, que será executada por mecanismos de raciocínio de tal forma a atender as consultas da aplicação. O uso dos padrões W3C permite Machine to Machine (M2M) trazendo o ML cada vez mais presente no nosso dia a dia.
Nenhum comentário:
Postar um comentário