Por Martin Heinz em 25/04/20 no site Medium
The release of Python 3.9 is still quite a while away (5.10.2020), but with the last alpha (3.9.0a5) release out and first beta in near future, it feels like it’s time to see what new features, improvements and fixes we can expect and look forward to. This article won’t be an exhaustive list of every change, but rather a list of the most interesting and noteworthy things to come with the next version for us — developers. So, let’s dive in!


Installing Beta Version
To be able to actually try anything contained in the alpha/beta versions of Python 3.9, we first need to install it. Ideally alongside our existing Python 3.8 (or another stable version) installation so that we don’t mess up our default interpreter. So, to install the latest, greatest version:
wget https://www.python.org/ftp/python/3.9.0/Python-3.9.0a5.tgz tar xzvf Python-3.9.0a5.tgz cd Python-3.9.0a5 ./configure --prefix=$HOME/python-3.9.0a5 make make install $HOME/python-3.9.0a5/bin/python3.9
After running this you should be greeted by IDLE and message like:
3.9.0a5 (default, Apr 16 2020, 18:57:58) [GCC 9.2.1 20191008] on linux Type "help", "copyright", "credits" or "license" for more information.
New Dict Operators
The most notable new feature is probably the new dictionary merging operator —
| or |=. Until now, you would have to choose from one of the following 3 options for merging dictionaries:# Dictionaries to be merged:
d1 = {"x": 1, "y": 4, "z": 10}
d2 = {"a": 7, "b": 9, "x": 5}
# Expected output after merging
{'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9}
# ^^^^^ Notice that "x" got overridden by value from second dictionary
# 1. Option
d = dict(d1, **d2)
# 2. Option
d = d1.copy() # Copy the first dictionary
d.update(d2) # Update it "in-place" with second one
# 3. Option
d = {**d1, **d2}
The first option above uses
dict(iterable, **kwargs) function which initializes dictionaries - the first argument is a normal dictionary and the second one is a list of key/value pairs, in this case, it's just another dictionary unpacked using ** operator.
The second approach uses
update function to update the first dictionary with pairs from the second one. As this one modifies dictionary in-place, we need to copy the first one into the final variable to avoid modifying the original.
Third — last — and in my opinion, the cleanest solution is to use dictionary unpacking and unpack both variables (
d1 and d2) into the resulting one d.
Even though the options above are completely valid, we now have a new (and better?) solution using
| operator.# Normal merging
d = d1 | d2
# d = {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9}
# In-place merging
d1 |= d2
# d1 = {'x': 5, 'y': 4, 'z': 10, 'a': 7, 'b': 9}
The first example above does very much the same as operator unpacking shown previously (
d = {**d1, **d2}). The second example, on the other hand, can be used for in-place merging, where the original variable ( d1) is updated with values from the second operand ( d2).Topological Ordering
Next new interesting (and little obscure) feature is part of
functools module. You can find it under TopologicalSorter class. This class allows us to sort graphs using topological ordering. What is that? you may ask. Topological ordering is such ordering where for 2 nodes u and v connected by directed edge uv (from u to v), u comes before v.
Before the introduction of this feature, you would have to implement it yourself using e.g. Khan’s algorithm or depth-first search which aren’t exactly simple algorithms. So, now in case need to — for example — sort dependant jobs for scheduling, you just do the following:
from functools import TopologicalSorter
graph = {"A": {"D"}, "B": {"D"}, "C": {"E", "H"}, "D": {"F", "G", "H"}, "E": {"G"}}
ts = TopologicalSorter(graph)
list(ts.static_order())
# ['H', 'F', 'G', 'D', 'E', 'A', 'B', 'C']
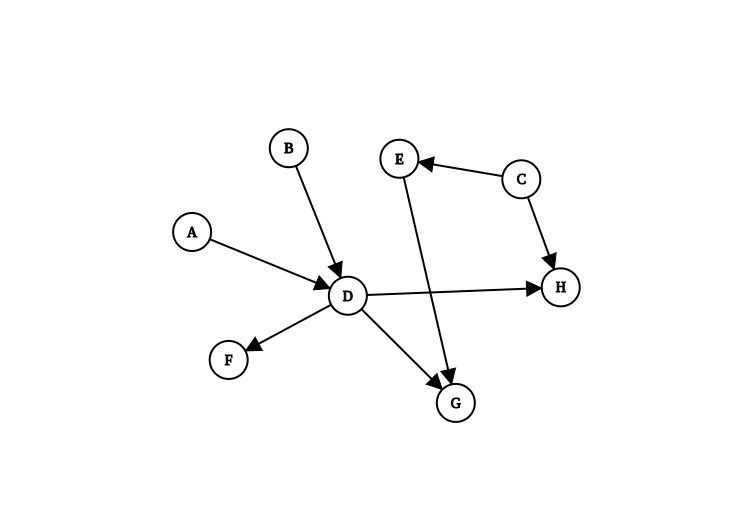
In the example above, we first create a graph using a dictionary, where keys are outgoing nodes and values are sets of their neighbours. After that, we create an instance of sorter using our graph and then call
static_order function to produce the ordering. Bear in mind that this ordering may depend on the order of insertion because when 2 nodes are in the same level of the graph, they are going to be returned in the order they were inserted in.
Apart from static ordering, this class also supports parallel processing of nodes as they become ready for processing, which is useful when working with e.g. task queues — you can find examples of that in Python library docs here.
IPv6 Scoped Addresses
Another change introduced in Python 3.9 is the ability to specify the scope of IPv6 addresses. In case you are not familiar with IPv6 scopes, they are used to specify in which part of the internet is the respective IP address valid. Scope can be specified at the end of IP address using
% sign - for example: 3FFE:0:0:1:200:F8FF:FE75:50DF%2 - so this IP address is in scope 2 which is link-local address.
So, in case you need to deal with IPv6 addresses in Python, you can now do so like this:
from ipaddress import IPv6Address
addr = IPv6Address('ff02::fa51%1')
print(addr.scope_id)
# "1" - interface-local IP address
There is one thing you should be careful with when using IPv6 scopes though. Two addresses with different scopes are not equal when compared using basic Python operators.
New math Functions
Meanwhile in the
math module, a bunch of miscellaneous functions were added or improved. Starting with the improvement to one existing function:import math # Greatest common divisor math.gcd(80, 64, 152) # 8
Previously, the
gcd function which calculates the Greatest Common Divisor could only be applied to 2 numbers, forcing programmers to do something like this math.gcd(80, math.gcd(64, 152)), when working with more numbers. Starting with Python 3.9, we can apply it to any number of values.
The first new addition to
math module is math.lcm function:# Least common multiple math.lcm(4, 8, 5) # 40
math.lcm calculates Least Common Multiple of its arguments. Same as with GCD, it allows a variable number of arguments.
The 2 remaining new functions are very much related. These are
math.nextafter and math.ulp:# Next float after 4 going towards 5 math.nextafter(4, 5) 4.000000000000001 # Next float after 9 going towards 0 math.nextafter(9, 0) 8.999999999999998 # Unit in the Last Place math.ulp(1000000000000000) 0.125 math.ulp(3.14159265) 4.440892098500626e-16
The
math.nextafter(x, y) function is pretty straightforward - it's next float after x going towards y while taking into consideration floating-point number precision.
The
math.ulp on the other hand, might look a little weird... ULP stands for "Unit in the Last Place" and it's used as a measure of accuracy in numeric calculations. The shortest explanation is using an example:
Let’s imagine that we don’t have 64 bit computer. Instead, all we have is just 3 digits. With these 3 digits, we can represent a number like
3.14, but not 3.141. With 3.14, the nearest larger number that we can represent is 3.15, These 2 numbers differ by 1 ULP (Units at the last place), which is 0.1. So, what the math.ulp returns is equivalent of this example, but with actual precision of your computer. For proper example and explanation see nice writeup at https://matthew-brett.github.io/teaching/floating_error.html.New String Functions
math module is not the only one that got some new functions. Two new convenience functions for strings were added too:# Remove prefix
"someText".removeprefix("some")
# "Text"
# Remove suffix
"someText".removesuffix("Text")
# "some"
These 2 functions perform what you would otherwise achieve using
string[len(prefix):] for prefix and string[:-len(suffix)] for suffix. These are very simple operations and therefore also very simple functions, but considering that you might perform these operations quite often, it’s nice to have built-in function that does it for you.Bonus: HTTP Codes
Last but not least, well actually… are HTTP status codes added to
http.HTTPStatus. Namely, those are:import http http.HTTPStatus.EARLY_HINTS # <HTTPStatus.EARLY_HINTS: 103> http.HTTPStatus.TOO_EARLY # <HTTPStatus.TOO_EARLY: 425> http.HTTPStatus.IM_A_TEAPOT # <HTTPStatus.IM_A_TEAPOT: 418>
Looking at these status codes, I can’t quite see why would you ever use them. That said, it’s great to finally have I’m a Teapot status code at our disposal. It’s a great quality of life improvement that I can now use
http.HTTPStatus.IM_A_TEAPOT when returning this code from production server ( sarcasm, Please never do that...).Conclusion
Probably not all of these changes are relevant to your daily programming, but I think it’s good to be at least aware of the first 2 additions (
| operator and TopologicalSorter) as they might come in handy at some point. That said Python 3.9 is still in alpha phase, so there still might be some additional changes up until 18.5.2020 (first beta release). But even then you should not use this version, as it is not stable nor production ready (not at least until October).
If you liked this article you should check you other of my Python articles below!
Nenhum comentário:
Postar um comentário