Em 21/09/2017 no site Medium

Machine Learning é uma técnica de Inteligência Artificial que permite que a máquina aprenda através de exemplos, exatamente como os seres humanos.
Pouca gente percebe, mas a Inteligência Artificial já faz parte do nosso dia a dia:
- Os emails do seu Gmail já são classificados automaticamente como Spam ou Não Spam
- O seu Facebook já é capaz de identificar o rosto de cada um dos seus amigos e marcá-los automaticamente nas fotos do rolê do final de semana
- Quando você faz uma compra online e recebe sugestões de produtos que foram selecionados por uma máquina que se baseia nas suas escolhas anteriores.
Ok, então a gente já se aproveita das técnicas de Machine Learning, sem perceber, mas como essa coisa toda funciona na prática? É isso que a gente vai descobrir agora!
Você sabe me dizer o que é um gato? E o que é um cachorro?
Se você é um humano seria muito simples responder a esta questão, provavelmente desde criança você viu uma série de exemplos de miaus e au-aus e sem perceber você estava sendo treinado para realizar esta classificação.
A resolução de problemas de classificação utilizando aprendizado de máquina ou machine learning, seguem exatamente o mesmo princípio. Oferecemos vários exemplos para a máquina e indicamos o que é um gato e o que é um cachorro e a partir daí a máquina é capaz de identificar o padrão encontrado observando todos os exemplos anteriores.
Parece mágica, macumba ou ilusionismo, mas é pura ciência! Vamos lá entender a partir de um exemplo como isso funciona e em breve você será capaz de criar seus próprios algoritmos de classificação…
1. Definição do Problema:
A primeira coisa é ter claro o que queremos classificar, existem os casos clássicos que classificam emails como spam ou não spam, em imagens que reconhecem sorrisos ou não sorrisos e nos carros autônomos podemos classificar um terreno com aclive e sem aclive, entre tantos outros exemplos.
No nossso problema queremos identificar o que é um gato e por eliminação, se o bichinho não for um gato, vamos identificá-lo como cachorro. Você deve se perguntar o que diferencia um gato de um cachorro, algumas características extremamente similares, como o fato de todos ele terem 4 patas não vão nos ajudar nessa diferenciação, portanto devem ser evitadas.
Levantamos então, três características do nosso gato referência:
- É fofinho?
- Tem orelhinha pequena?
- Faz miau?
Se a resposta para cada uma destas perguntas for SIM responderemos com 1 e se for NÃO responderemos com 0.

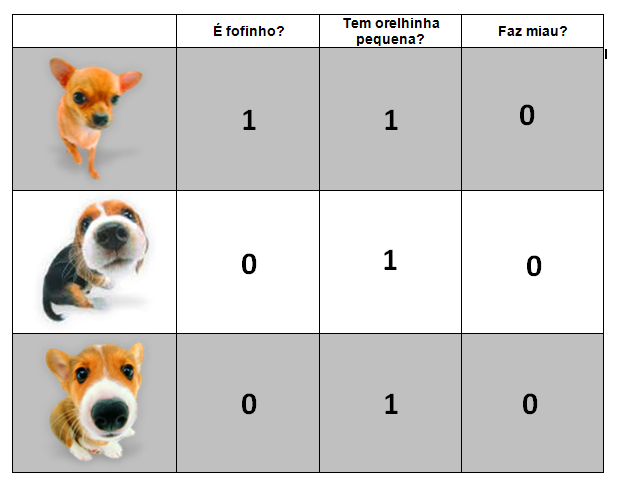
2. Definindo nosso dataset:
Agora vamos criar nosso dataset, os dados que vamos lidar, para isso devemos traduzir essa informação “humana” contida na nossa tabela, para uma linguagem que seja entendida pelas máquinas.
Vamos utilizar a linguagem Python e transformar cada bichinho em uma variável, em cada uma iremos inserir características já definidas na tabela.
O primeiro valor corresponde a pergunta: É fofinho? o segundo corresponde a tem orelhinha pequena? e o terceiro a faz miau? Para cada pergunta vamos preenchendo com os valores 1 para resposta SIM e 0 para a resposta NÃO. Então mãos a obra!
bichinho1 = [1, 1, 1] bichinho2 = [1, 0, 1] bichinho3 = [0, 1, 1] bichinho4 = [1, 1, 0] bichinho5 = [0, 1, 0] bichinho6 = [0, 1, 0]
Foi bem tranquilo fazer esta tradução, certo? Agora só precisamos agrupar todos os nossos animaizinhos no nosso pequeno banco de dados. Para fazer isso vamos criar uma nova variável e colocar todos os nossos bichinhos lá dentro.
dados = [bichinho1, bichinho2, bichinho3, bichinho4, bichinho5, bichinho6]
O próximo passo é contar para a nossa máquina qual dos nossos bichinhos do dataset é gato e qual é cachorro. Observe que só definimos as características de cada um, agora continuamos seguindo a nossa tabela de referência e vamos informar para a máquina quem é quem.
Precisamos portanto colocar um label, um rótulo ou uma marcação em cada um dos itens do nosso dataset.
Como a máquina prefere lidar com números, vamos criar a seguinte convenção:
1 = Gato
-1 = Cachorro
Agora informamos a nossa convenção para a máquina:
marcacoes = [1, 1, 1, -1, -1, -1]
Falamos que os três primeiros bichinhos são gatos e os três últimos são cachorros, simples assim.
3. Criando modelos
Agora vamos começar a utilizar as técnicas de Machine Learning propriamente ditas.
Existem uma série de diferentes abordagens como SVM, Árvores de decisão, K-Nearest Neighbors, Naive Bayes entre tantas outras.
Existem uma série de diferentes abordagens como SVM, Árvores de decisão, K-Nearest Neighbors, Naive Bayes entre tantas outras.
Neste exemplo vamos utilizar a Naive Bayes. A abordagem Naive Bayes é baseada no teorema de probabilidade de Bayes e tem como objetivo calcular a probabilidade que uma amostra desconhecida pertença a cada uma das classes possíveis, ou seja, predizer (ou adivinhar) a classe mais provável.
Devemos em primeiro lugar importar as funções necessárias através do comando:
from sklearn.naive_bayes import MultinomialNB
OBS: Caso você nao tenha instalado a biblioteca sklearn, instale através dos comandos:
pip install scikit-learn
ou utilizando o ambiente anaconda, com o comando:
conda install scikit-learn
Agora vamos criar o nosso modelo. Fazemos uma chamada da função do scikit-learn que já realiza a adequação dos nossos dados ao algoritmo de classificação Naive Bayes. E por fim, passamos os nossos dados e nossas marcações para o nosso modelo ser gerado. Ou seja, estamos passando todo o conhecimento para o algoritmo de classificação: estes são os nossos bichinhos (dataset) e eu os classifiquei de acordo com estas marcações.
modelo = MultinomialNB() modelo.fit(dados,marcacoes)
4. Fazendo Predições
Agora queremos mostrar um novo bicho e identificar em qual categoria ele se enquadra: gato ou cachorro?
bicho_misterioso1 = [1, 1, 1] bicho_misterioso2 = [1, 0, 0] bicho_misterioso3 = [0, 0, 1]
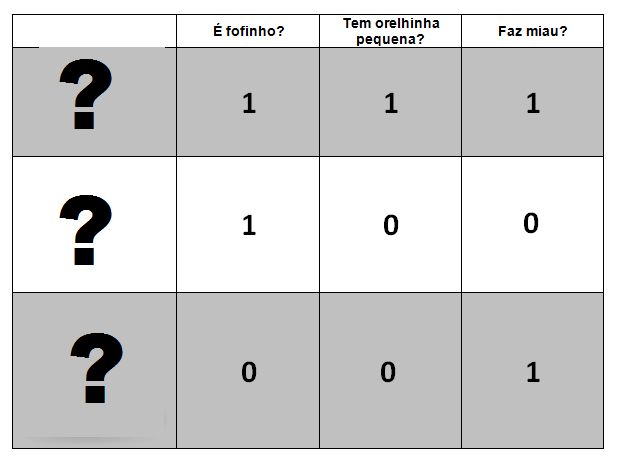
Agrupamos todos os nossos bichos misteriosos numa única variável.
teste = [bicho_misterioso1, bicho_misterioso2, bicho_misterioso3]
5. Observando Resultados:
Agora vamos ver se o nosso classificador está trabalhando bem, para tanto passamos todos os nossos bichinhos misteriosos que estão na variável teste para a predição, para que a máquina tente “adivinhar” o resultado.
resultado = modelo.predict(teste)
E agora como vamos saber se a máquina chegou em uma classificação correta?
Vamos considerar que já sabemos as respostas para cada um dos bichos misteriosos, estamos querendo verificar se o nosso classificador vai funcionar bem.
O primeiro bicho misterioso é um gato. O segundo bicho misterioso é um cachorro. E o terceiro bicho misterioso é um gato também.
Agora vamos passar essa informação para a máquina criando o nosso marcacoes_teste.
marcacoes_teste = [1,-1, 1]
E para realmente verificar, vamos comparar o resultado com as nossas marcacoes_teste.
print(“Resultado: “) print(resultado)
print (“Marcacoes: “) print(marcacoes_teste)
Ao rodar o nosso Algoritmo vamos ter como resposta:
Resultado [ 1 1 1] Marcações [1 -1 1]
Isso significa que a máquina chutou que os animais misteriosos são:
Resultado[ Gato, Gato, Gato]
e a resposta correta deveria ser
Marcacoes [Gato,Cachorro,Gato]
Nada mau para uma base de dados tão pequena! Quanto maior o dataset, maior a chance da máquina oferecer a resposta correta.
Portanto o nosso algoritmo tem a acurácia de 66,66%, ou seja, ele acertou 2 bichos misteriosos do nosso total de 3.
Você pode testar este mesmo algoritmo com diferentes abordagens de Machine Learning como SVM, Árvores de Decisão ou K-Nearest Neighbors, baixe o código e faça seus testes!
Caso este texto tenha sido útil, compartilhe a sua experiência aqui com a gente! Até a próxima :)
O código completo deste exemplo pode ser visto aqui:
Nenhum comentário:
Postar um comentário