Por Waldemar Dibiazi Junio
Em 11/07/2017 no
site Profissionais TI
Este artigo abordará como configurar e executar um serviço do SGBD Microsoft SQL no sistema operacional Linux sob um container Docker, utilizar a persistência de volumes de dados sob o container, bem como, explorar a execução de binários como o sqlcmd para estabelecer uma sessão com o serviço do SQL Server e realizar o processo de backup e restore de uma base de dados.
Um pouco de história
Docker é um projeto open source que permite automatizar o desenvolvimento, distribuição e execução de aplicações em Linux containers.
Um Linux container é um método para executar isoladamente um ou mais binários em um único host (hospedeiro), sem a necessidade de um hipervisor (que demandaria a instalação de um sistema operacional convidado).
O
projeto Docker pode ser instalado e configurado com facilidade não apenas em sistemas GNU/Linux, mas também em sistemas como Windows e Mac OS/X.
Diferentemente de uma tecnologia de virtualização como Linux KVM, VMWare vSphere, Xen e Hyper-V que demandam a instalação de um sistema operacional convidado, compartilham apenas o Kernel do host no qual estão sendo executados, onde binários e bibliotecas dentro de cada container são a priori restritos ao ambiente de execução de cada container.
Deste modo, cada aplicação/serviço em execução dentro de um container poderá ter seus binários e bibliotecas atualizados sem a preocupação de prejudicar outros containers.
Docker é baseado na tecnologia LXC (Linux Containers), mas temos outras tecnologias de containers como o Jails de sistemas BSD, assim como, temos tecnologias muito mais simples para criação de sandbox (que é base para a idéia empregada em Linux Containers), por exemplo, chroot, onde é possível isolar serviços como o Web Service Apache e o DNS Service Bind.
Deste modo, através do chroot podemos criar uma árvore de filesystem apenas com os arquivos necessários para o serviço, isolando um ou mais processos do serviço em questão, evitando que estes processos tenham acesso aos filesystems do host. Essa abordagem é muito útil em situações onde um serviço tem uma ou mais vulnerabilidades e uma delas foi explorada permitindo que um atacante obtenha um shell.
A partir do momento que este shell for obtido pelo atacante, o processo deste shell visualizará apenas a árvore do filesystem disponibilizada via chroot, criando assim uma sandbox que ajudará na contenção do ataque, contenção essa que se não fosse realizada permitiria ao atacante explorar outros arquivos e serviços no mesmo host.
O Docker foi desenvolvido inicialmente como uma API de alto nível que complementaria o LXC , mas a partir da versão 0.9 introduziu sua própria biblioteca, desenvolvida utlizando a linguagem GO.
Através do Docker é possível executar aplicações diversas como, por exemplo, servidores de banco de dados, web application service, servidores de banco de dados (alvo deste artigo).
Supondo que temos um host com Debian, é possível executarmos containers que disponibilize um sistema/distribuição Ubuntu, Suse ou CentOS, pois toda a árvore de filesystem contendo binários, arquivos de configuração, bibliotecas (dinâmicas e estáticas) particulares para cada distribuição estarão isoladas em cada container, onde o único elemento utilizado em comum por cada container é o kernel.
Iniciando os trabalhos:
A imagem de container Docker disponibilizada pela Microsoft que será utilizada é: microsoft/mssql-server-linux
Para este artigo utilizaremos o Docker Hub para realizar o pull da imagem acima mencionada.
A seguir temos os requisitos mínimos para poder utilizar a imagem de container Docker disponibilizada pela Microsoft:
- Docker Engine 1.8 ou superior
- Mínimo de 4 GB de espaço em disco
- Mínimo de 4 GB de RAM
- Configurar uma senha forte para a conta de administrador do serviço do SQL Server, senha essa contendo pelo menos 8 caracteres utilizando letras maiúsculas e minúsculas, números e/ou símbolos não alfanuméricos.
Para este artigo foi utilizada a distribuição Debian 9.
A instalação do Docker pode ser realizada de maneira simples através da etapas abaixo:
– Instale os pacotes que serão dependências no restante do processo de instalação do Docker Engine:
|
|
sudo apt install -y curl apt-transport-https \
software-properties-common ca-certificates
|
– Adicione a chave do repositório:
|
|
curl -fsSL https://yum.dockerproject.org/gpg | sudo apt-key add –
|
– Adicione o repositório ao sistema:
|
|
sudo add-apt-repository "deb https://apt.dockerproject.org/repo/ \
debian-$(lsb_release -cs) \
testing"
|
– Atualize o banco de dados de referência de pacotes do sistema:
– Instale o pacote do Docker Engine:
|
|
sudo apt-get install -y docker-engine
|
– Execute os daemons do Docker e ative o serviço na inicialização do sistema:
|
|
sudo systemctl start docker
sudo systemctl enable docker
|
– Adicione o atual usuário logado no grupo de usuário Docker. Essa ação fará com que não seja necessária a utilização do comando sudo para utilização docker.
|
|
sudo gpasswd -a "${USER}" docker
|
– Reinicie o sistema para testar a inicialização do serviço do Docker:
– Liste os containers criados (em execução e também que não estão em execução):
Obviamente a listagem não retornará nada pois não existem container criados.
– Crie e execute um container utilizando uma imagem de teste chamada hello-run
Esta ação fará com que o engine do Docker realize o pull da imagem diretamente do Docker Hub.
Após a execução do conteiner ele exibirá algumas mensagens, dentre elas: Hello from Docker !
Você poderá verificar que o host possui um container que não está em execução, pois o container criado e que entrou em execução apenas exibiu algumas mensagens relacionadas a teste e em seguida teve a execução finalizada.
Da mesma forma que existe um container que não está em execução, temos uma imagem que sofreu o download para o host, imagem essa utiliza de base para execução do nosso container de teste:
Vamos realizar o pull da imagem de container do SQL Server e utiliza-la para criar e executar o container que proverá um serviço de banco de dados da Microsoft sob o host atual.
Entretanto, antes disso iremos criar uma estrutura de diretórios que permitirá termos persistência dos dados do container, especificamente, do diretório /var/opt/mssql que no caso é o diretório dentro da estrutura do container que armazenará os datafiles dos bancos de dados do SQL Server.
É muito importante a configuração da persistência, pois ao finalizar o container por padrão os dados serão perdidos e em muitas situações a perda dos dados gerados durante a execução do container não é aceitável. Entretanto, tudo dependerá da finalidade do container, afinal, podemos executar um container, gerar informações nele, mas tais informações poderem ser descartadas ou as mesmas já terem sido armazenadas em outro host ou container que utiliza persistência de dados.
Portanto, crie a seguinte estrutura de diretórios:
|
|
mkdir /data/containers/SQLServer01/mssql -p
|
Em seguida execute o container, que será nomeado como SQLServer01.
|
|
docker run –name SQLServer01 -e ‘ACCEPT_EULA=Y’ \
-e ‘SA_PASSWORD=#AdminSQLServer2017’ \
-p 1433:1433 -v /data/containers/SQLServer01/mssql:/var/opt/mssql \
-d microsoft/mssql-server-linux
|
Aguarde o pull (download) da imagem para que o container seja criado e entre em execução.
O comando acima pode ser entendido da seguinte maneira:
run – esta opção realiza três ações: pull da imagem, criação do container e em seguida execução do container criado.
-e – permite a criação de variáveis de ambiente sob o ambiente de execução do container. No caso acima, foram criadas duas variáveis de ambiente: ACCEPT_EULA recebendo o valor Y e SA_PASSWORD recebendo o valor #AdminSQLServer2017 (que será a senha da conta System Administrator do SQL Server). Deste modo, durante a execução do binário existente na imagem que sofreu o pull, este binário irá verificar a existências destas variáveis e utilizar os valores setados nelas.
A variável ACCEPT_EULA permite que definir se os termos da licença de uso serão aceitos.
-p – permite realizar o mapeamento de portas. No caso acima, qualquer conexão a porta 1433 ( valor numérico a esquerda dos : ) será redirecionada para a porta 1433 ( valor numérico a direita dos : ) em listening no container.
-d – executará o container em modo background.
-v – anexará um volume externo a um volume dentro do container, no caso, teremos o mapeamento do diretório /data/containers/SQLServer01/mssql existente no host para o diretório /var/opt/mssql existente no container.
Portanto ação de criação, exclusão e alteração ocorrida em /var/opt/mssql dentro do container também ocorrerá em /data/containers/SQLServer01/mssql (que encontra-se acessível no host que executa o container).
–name – Define o nome que o container terá ao ser criado.
Em seguida verifique se o container está em execução:
Caso o container não seja listado, então execute novamente o comando docker run sem a opção -d para podermos visualizar no console qualquer mensagem de erro durante a inicialização dos binários do container.
Um erro muito comum é a falta de memória no host, lembrando que a recomendação mínima são 4 GB.
Verificada a existência de algum erro (por exemplo, quantidade de memória insuficiente), abra outro terminal e pare o container com o comando:
Para executar novamente o container, basta executar:
Verifique novamente se o container está em execução:
Com o container em execução iremos estabelecer uma sessão de usuário com o serviço em execução sob o Container.
Dentro das das vantagens clássicas de container temos isolamento, portabilidade e flexibilidade e graças a isso podemos não apenas executar binários e bibliotecas existentes em uma imagem na forma de um container que atuará como serviço, mas também podemos simplesmente realizar a chamada a outros binários existentes no container já em execução, por exemplo, um binário que represente uma ferramenta de linha de comando que faz parte da solução empacotada dentro da imagem.
Iremos iniciar o binário bastante conhecido por DBAs que trabalham com SQL Server, o sqlcmd para estabelecermos uma sessão de usuário com o serviço do SQL Server.
|
|
docker exec -it SQLServer01 /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P #AdminSQLServer2017
|
A opção exec realiza a chamada a binários existentes dentro de um container em execução, ou seja, sem precisar criar um novo container apenas para executar um binário já existente na imagem que foi utilizada de base para a criação do container anterior.
Já as opções -it permitem que durante a execução do binário sqlcmd seja possível estabelecer a interação entre entre o shell e o binário em execução no momento.
Após a execução do binário sqlcmd será exibido o prompt
1>
Execute a instrução SQL select a seguir acompanhada da instrução GO:
|
|
SELECT Name from sys.Databases;
GO
|
Serão exibidos os databases padrão do SQL Server, no caso:
Realizaremos a seguir algumas operações simples em SQL:
- Criação de um database;
- Abertura do database;
- Criação de uma tabela;
- Inserção de registros nesta tabela;
- Consulta de registros;
1
2
3
4
5
6
7
8
9
10
11
12
13
|
create database empresa;
go
use empresa;
go
create table cliente (codigo integer, nome varchar(80), primary key(codigo));
go
insert into cliente values (1,”Linus Torvalds”);
go
insert into cliente values (2,”Dennis Ritchie”);
go
select * from cliente;
go
exit
|
Com a sessão finalizada com a instrução exit, iremos parar o container e inicia-lo novamente para comprovar que a persistência de dados está sendo realizada corretamente.
Verifique se o container não encontra-se mais em execução:
Liste os arquivos e diretórios criados no nosso diretório utilizado para persistência de dados do container:
|
|
ls -l /data/containers/SQLServer01/mssql/data
|
Podemos constatar que os datafiles do nosso database empresa, bem como os datafiles dos bancos de dados default do
SQL Server foram criados efetivamente no diretório de persistência.
Inicie o container novamente e verifique que o binário do serviço do SQL Server em execução sob o container irá obter acesso aos datafiles:
Execute o binário do cliente sqlcmd novamente:
|
|
docker exec -it SQLServer01 /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P #AdminSQLServer2017
|
Liste os databases existentes:
|
|
SELECT Name from sys.Databases;
go
|
Executando backup completo do database empresa:
|
|
docker exec -it SQLServer01 /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P #AdminSQLServer2017 -Q “BACKUP DATABASE [empresa] to disk = ‘/var/opt/mssql/backup-empresa.sql'”
|
Devido o mapeamento de volume de dados no container, podemos copiar o arquivo backup-empresa.sql (existentente em /data/containers/SQLServer01/mssql) para outro local.
Restaurando o backup completo do database empresa:
|
|
docker exec -it SQLServer01 /opt/mssql-tools/bin/sqlcmd -S localhost -U sa -P #AdminSQLServer2017 -Q “RESTORE DATABASE [empresa] from disk = ‘/var/opt/mssql/backup-empresa.sql’ WITH REPLACE”
|
Este é um exemplo simples de backup e restore, entretanto, vale salientar que existem outras opção relacionadas ao backup como, por exemplo, backup do log de transações, entre outras.
O objetivo do artigo foi apenas demonstrar a chamada de binários existentes no container não apenas para prover um serviço de banco dados, mas também utilizar ferramentas como sqlcmd existente na árvore do filesystem do container.
No próximo artigo iremos ver a instalação e configuração de um Cluster utilizando Docker Swarm e o gerenciamento de containers utilizando uma web interface.

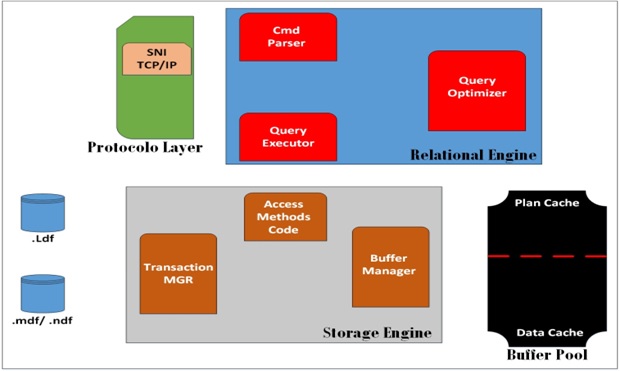 Figura 1 - Estrutura dos componentes utilizados pelo comando select.
Figura 1 - Estrutura dos componentes utilizados pelo comando select. Figura 2 - Representação do inicio do ciclo de vida do comando select.
Figura 2 - Representação do inicio do ciclo de vida do comando select. Figura 3 - Comportamento do Command Parse após o processo de reconhecimento dos pacotes.
Figura 3 - Comportamento do Command Parse após o processo de reconhecimento dos pacotes. Figura 4 - Ciclo de vida do comando select concluído e dados apresentados para o usuário.
Figura 4 - Ciclo de vida do comando select concluído e dados apresentados para o usuário.






