Big Data 1.0
A primeira era da explosão de dados foi chamada de Big Data 1.0. Ela resumiu-se em criar estruturas para armazenamento e processamento de grandes volumes de dados que já não eram suportados pelos sistemas operacionais tradicionais. A preocupação das empresas era criar sistemas capazes de processar grandes volumes de dados.
Foi nesse contexto que Doug Cutting, um engenheiro de software da Empresa Apache, formado em Stanford, na Califónia – uma das universidades mais bem conceituadas nos Estados Unidos – desenvolveu uma solução baseada em armazenamento e processamento paralelo. O sistema recebeu o nome de
Hadoop, inspirado pelo elefante amarelo de brinquedo de seu filho.
Veja na Figura 1 abaixo Doug com o brinquedo de seu filho.
Tanto a empresa Apache, quanto Doug consideram que o mais importante para a transformação digital são os sistemas de código aberto, a distribuição do código do Hadoop acelerou a tecnologia mundial na forma de armazenar e processar os dados utilizando o processamento paralelo.
No processamento paralelo, os dados são mapeados (Map), armazenados em vários computadores (clusters) no sistema de arquivos distribuído do Hadoop (HDFS) e replicados (cada pedaço da informação é copiada em mais de um computador) para garantir que não haverá perda de informação caso algum computador perca o sinal. Vários computadores processam os mesmos dados (processados paralelamente) e reduzidos (Reduce) a uma única saída.
De forma bem resumida, a tecnologia Hadoop é o
HDFS (Hadoop File System), sistema de arquivos distribuídos com alto desempenho de acesso e o
MapReduce, processamento paralelo de alta disponibilidade.
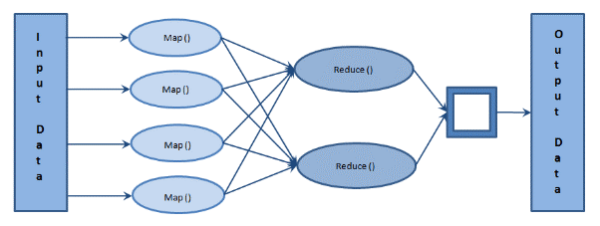
Vide Figura 2 abaixo.
Na figura 2 temos uma entrada (Input Data) e 4 replicações diferentes (4 Map{}). Cada Map{} tem 2 saídas e são reduzidos (2 Reduce{}), com uma saída (Output Data). Na prática, todos os dados processam uma parte e fornecem apenas uma resposta com a garantia de que nada será perdido caso algum servidor caia.
Big Data 2.0
Já consolidada a tecnologia de processamento, a preocupação passou a ser em criar formas de aproveitar a interatividade na internet a favor das empresas, descobrir o que a web poderia fazer por elas e como poderiam melhorar as coisas que sempre fizeram. Deu-se então o início da era do Big Data 2.0 cujo objetivo é extrair valor de grandes massas de dados e, para isso, era necessário aperfeiçoar a tecnologia, ou seja, desenvolver uma nova arquitetura para essa etapa de interatividade.
Doug Cutting juntamente com alguns ex-funcionarios da Google e do Facebook desenvolveram uma nova versão para o
Hadoop com uma camada chamada
Yarn capaz de suportar conectividade de outros sistemas, agendamento e um novo gerenciamento de tarefas e recursos, incluindo a possibilidade de coleta e análise de dados em tempo real
RT Stream Graph.
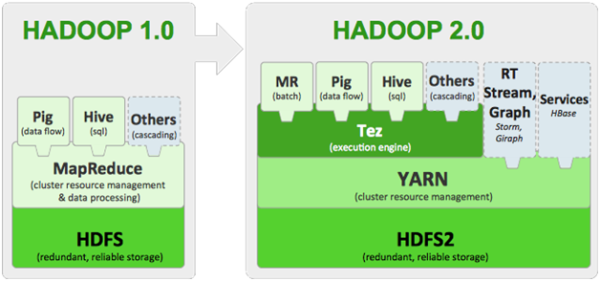
Veja na Figura 3 a evolução da arquitetura do Hadoop 1.0 para o Hadoop 2.0.
Imagine quantos clusters (computadores) a Google utiliza hoje para manter seus sistemas de buscas e para gravar o histórico de atividades. Imagine quantos clusters são necessários para armazenar as informações de usuários do Facebook, Twitter e de grandes empresas de varejo e e-commerce.
Agora, muito provavelmente você deve estar se perguntando: Qual o interesse das empresas em manter toda essa tecnologia e o que elas ganham com isso?
O principal interesse das grandes empresas que fornecem serviços gratuitos em nuvem é coletar Dados. Esses dados acumulados nos servidores em nuvem possuem valor, são experiências de usuário, dados históricos de vendas, utilizados e transformados em oportunidades de negócio. Isso gera receita para as empresas. Elas possuem o que chamamos de Novo Petróleo.
Isso mesmo, Dados são o Novo Petróleo!
O Hadoop 2.0 é a porta de entrada para o trabalho de Data Science nas empresas. Ele integrou em sua nova camada a execução novos sistemas para extraírem dados de redes sociais e possibilitarem a transformação desses dados em informações de valor em tempo real.
O objetivo do Big Data 2.0 é justamente através da conectividade e interatividade com a internet, possibilitar a tomada de decisões estratégicas rápidas, reduzir margens de erro, aproveitando os sistemas de análise em real time para trazer maior lucratividade para as empresas.
Sistemas de recomendação em anúncios são as fontes mais lucrativas. As empresas reconhecem padrões nos dados e conseguem prever comportamentos e recomendar os produtos que provavelmente a pessoa compraria baseadas em sua experiência e também comparando com experiências de outros usuários com perfil de compras parecido.
O que você faz quando quer comprar algum produto? Pesquisa no Google. E você já percebeu que após uma breve pesquisa, começam a aparecer em quase todas as páginas no Google propagandas sobre o produto que você pesquisou?
O mesmo acontece com o Facebook, você com certeza já viu fake news de que o Facebook passaria a ser cobrado, porém na página inicial temos a informação “Abra uma conta. É gratuito e sempre será.”
Então quem paga por tudo isso?
Vamos lá, sempre que você clica para ler uma publicidade, outros anúncios daquele mesmo produto aparecem em todas as páginas. Você faz isso de forma automática e nem percebe e, a partir daí esses anúncios te perseguem até que você pensa, “é a lei da atração”, e quando enfim aparece a publicidade que atende a sua necessidade, você clica e faz a compra.
Isso mesmo, as empresas ganham dinheiro sugerindo publicidade baseada em dados de suas atividades.
Eu não sei se você ficou sabendo, mas o Facebook possui uma função que mostra para os usuários onde os anunciantes obtiveram os dados deles e porque eles estão vendo o anúncio.
Vamos brincar de detetives 🙂
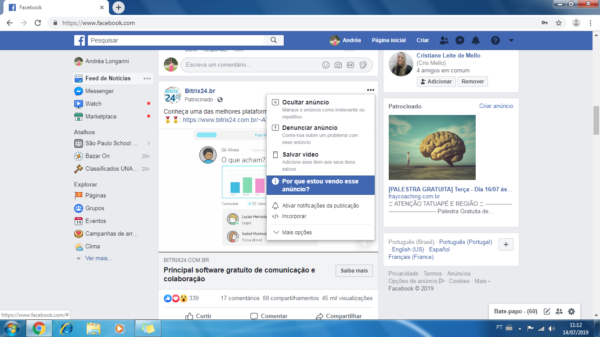
Para obter essas informações, clique nos três pontinhos “…” na parte superior direita nos anúncios sugeridos em sua linha do tempo, em seguida clique em “Porque estou vendo esse anúncio?” como mostra a Figura 4.
Figura 4
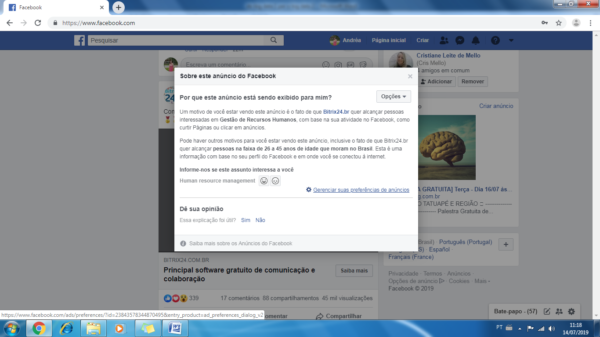
Abaixo, na figura 5, segue a explicação que apareceu quando cliquei para saber o porquê do anuncio aparecer como sugestão na minha linha do tempo.
Para aperfeiçoar o algoritmo de recomendação, ainda na figura 5, eles fazem duas perguntas. “Informe-nos se este assunto interessa a você”, nessa opção você tem dois emojis um feliz e um triste para demonstrar seu sentimento em relação ao anuncio. A outra pergunta é “Essa explicação foi útil? Sim Não”. Tudo para que você expresse sua satisfação, tanto com o tema da publicidade, quanto com a explicação sobre a recomendação do anúncio.
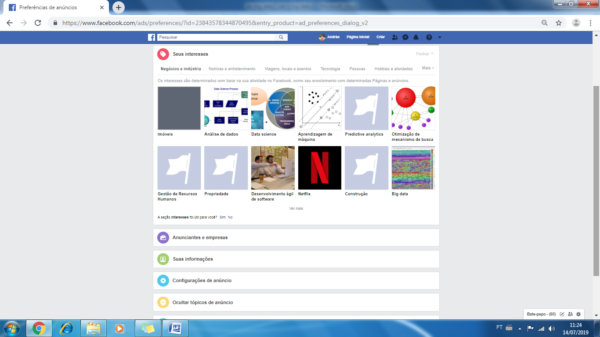
Perceba que na figura 5, além das perguntas há um link para você “Gerenciar suas preferências de anúncios”. Essa pagina contém muita informação sobre suas preferências, clique e ficará surpreso ao ver o quanto eles sabem sobre você.
No meu caso, me interesso bastante por temas de Ciência de Dados, o que ficou bem claro na primeira sessão de Negócios e indústria. No caso do anuncio sugerido da Bitrix24.br, apareceu devido ao interesse registrado em Gestão de Recursos Humanos (Veja na Figura 6), eu devo ter clicado para ver algum anuncio de sistema parecido, minha atividade ficou gravada e o algoritmo de recomendação utilizou essa informação me colocando como público alvo da campanha patrocinada (paga pelo anunciante ao Facebook).
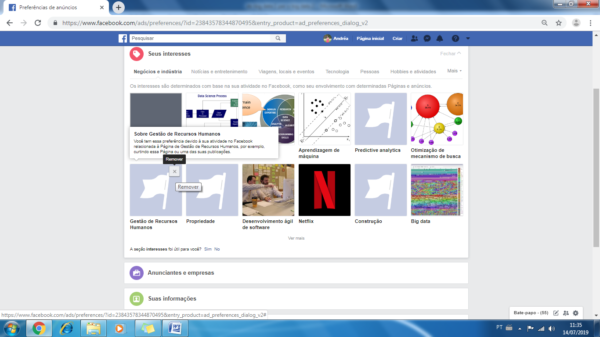
Você pode fazer algumas configurações para aperfeiçoar sua experiência. Sugiro que verifique agora mesmo sua conta e explore essas opções. Além disso, você pode eliminar os temas de menor interesse, ao posicionar o mouse sobre o item, aparecerá a opção para remover conforme mostra a Figura 7.
Pesquisando informações que a Google armazena sobre você
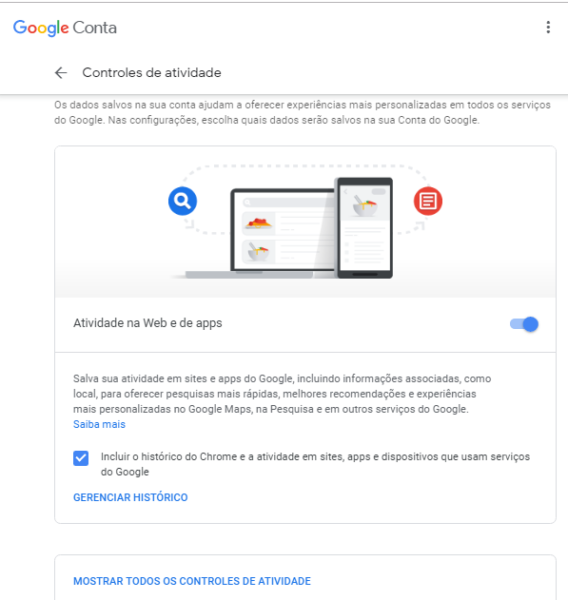
Faça login na conta do Google/Gmail, depois copie e cole em seu navegador o link
https://myaccount.google.com/intro/activitycontrols/search e clique em “Gerenciar Histórico”, depois clique em “Mostrar Todos os Controles de Atividade” aparecerá a pagina conforme a figura 8, você verá tudo que eles sabem sobre você!
Bom, esses são só dois exemplos para te mostrar o que anda acontecendo na internet por aí.
Assim como esses exemplos que demonstramos aqui, muitas empresas de varejo e e-commerce estão utilizando históricos de navegação em suas páginas para explorar os dados de buscas e compras, a partir desses dados, junto aos seus dados de cadastro, aplicam aprendizagem de máquina e utilizam os resultados para fazer publicidade e recomendação de produtos e serviços.
Passou a época de imprimir folhetos e entregar nas ruas próximas dos estabelecimentos comerciais, o comportamento do consumidor mudou, ele está na internet a alguns cliques de você.
Agora você entendeu por que as empresas estão fazendo a transformação digital?
Para extraírem informações de valor de seus dados e alcançarem os consumidores de seus produtos e serviços.
Nós não temos tantas informações de pesquisa de produtos e serviços como a Google, não temos informações de comportamento dos usuários como o Facebook, mas podemos utilizar os dados que temos para criar estratégias e tomar decisões baseadas em dados.
Hoje apenas 20% dos dados são utilizados pelas empresas para a tomada de decisão estratégica, são os dados estruturados, ou seja, dados organizados em tabelas de sistemas ERP, onde é possível, utilizando os sistemas tradicionais, construir relatórios de acompanhamento do desempenho. Para extrair mais valor desses dados, podemos aplicar algoritmos de predição utilizando os dados históricos para treinar um modelo de aprendizado de máquina que poderá direcionar os passos futuros de seu negócio.
Além disso, temos os outros 80% de dados não estruturados, são dados de voz (ligações), vídeos (monitoramento e vigilância), textos de e-mail, histórico de atendimento em sistemas de SAC e CRM, esses dados também podem ser explorados para gerar conhecimento e valor como fonte de oportunidades de negócios.
Não importa o tamanho ou a forma da sua base de dados, com o Big Data 2.0 não há limites!!!
É possível armazenar dados, utilizar as técnicas de Data Science (Ciência de Dados) para reconhecer padrões, classificar, identificar fraudes, fazer recomendação de produtos, conter possíveis perdas de clientes, etc.
O mundo virtual mudou a logística de compra e venda.
Há muitas possibilidades para sua empresa crescer, você não pode ficar aí parado vendo tudo isso acontecer.
Se beneficie dessas tecnologias para saber como extrair valor de seus dados.
Temos consultores que podem ajudar você nessa nova jornada para a Transformação Digital.
Fontes de pesquisa:
FAWCETT, T; PROVOST, F; BOSCATO, M. Data Science para Negócios. 1ª Edição. Rio de Janeiro: Alta Books, 2016.