 |
| Medium |
Um dos desafios do ramo da inteligência artificial é a análise e compreensão de texto, visto que até pouco tempo, esta era uma competência que apenas humanos conseguiam realizar de forma efetiva.
Existem diversas técnicas no mercado para realizar análise de texto, vamos utilizar aqui algumas técnicas de vetorização e processamento de dados para poder classificar como positiva ou negativa as avaliações do IMDB sobre filmes.
Neste post, iremos utilizar python 3 para fazer a análise e o google colaboratory para rodar nossos códigos o/.
Inicialmente vamos importar algumas bibliotecas e carregar nosso dataset:
Acima importamos a biblioteca pandas que nos auxilia a trabalhar com dataframes ou tabelas no python.
Esses comandos terão a saída conforme abaixo:
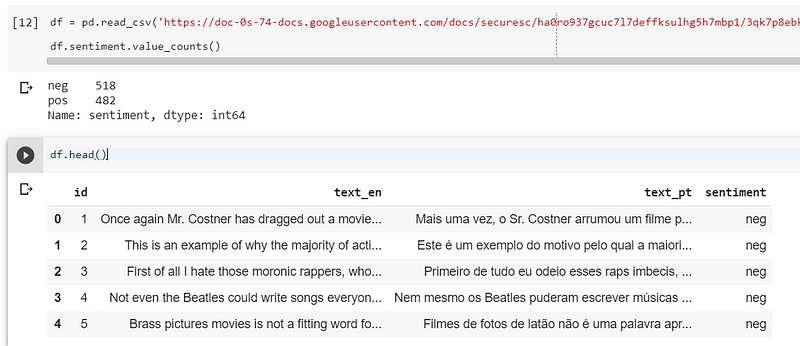
Veja que carregamos o dataset com 1000 registros, entretanto esse dataset possui aproximadamente 50k registros!!
Como modelos de machine learning trabalham melhor com valores numéricos, vamos modificar a coluna sentimento para 0=negativo e 1=positivo:
Apenas alguns conceitos antes, para processamento de linguagem natural, temos o conceito de n-grama, que consiste no agrupamento de palavras, então temos que um n-grama de tamanho um é um unigrama, de tamanho dois é um bigrama e assim por diante.
Esses n-gramas não são nada mais do que combinações de palavras. Para a frase: “Hoje é dia de sol” temos os unigramas:
Hoje, é, dia, de, sol
Neste caso cada palavra é um unigrama, para bigramas teríamos combinações de duas palavras e assim por diante.
Agora, para que possamos passar nossos dados para o modelo de machine learning, vamos vetorizar nossos dados, afinal como dito anteriormente, algoritmos de machine learning trabalham muito bem com números.
Para isso vamos utilizar a classe CountVectorizer da biblioteca scikit-learn. O scikit-learn é a biblioteca mais famosa para trabalhar com machine learning, recomendo que você veja a documentação aqui.
Perceba que aqui temos o parâmetro ngram_range onde passamos o range de n-gramas que queremos criar, para este exemplo vamos utilizar o unigrama.
Este código tem a função de criar um vetorizador com a representação numérica das palavras do nosso dataset, a variável “vect” é responsável por armazenar esse de-para das palavras para a representação numérica e a variável text_vect armazena uma matriz que representa nossos dados de avaliações do imdb já vetorizados.
Já temos nossos dados vetorizados, agora como gostamos de boas práticas, vamos separar nossa base em conjunto de treino e testes na proporção 70/30.
No código acima, importamos a função “train_test_split” do scikit-learn para separar os dados em treino e teste, veja que passamos a variável criada anteriormente “text_vect” que se trata dos nossos dados vetorizados, passamos a coluna “sentimento” que é o que queremos classificar e a variável “test_size” com o valor 0.3 que significa que queremos 30% dos dados como testes.
Agora que temos nossos dados de treino e testes, vamos partir para o modelo de machine learning, para este post, vamos utilizar o LogisticRegression do sklearn.
No código abaixo, importamos a classe LogisticRegression do scikit-learn para realizar o ajuste do modelo, instanciamos na variável clf e logo em seguida chamamos o método “fit” que é onde o treinamento do modelo acontece, perceba que passamos o X_train que são nossos dados de treino que utilizaremos para prever o y_train que são os sentimentos positivo e negativo.
Após rodar esse comando, podemos chamar o método “predict” para predizer nossos dados de teste e verificar a partir da métrica f1_score qual a porcentagem de acerto do nosso modelo:

Veja que obtivemos um score de 73%, nada mal hum? Com isso você conseguiu fazer um classificador de textos com técnicas simples de processamento de linguagem natural!! 😎
Apenas um detalhe, é que essa precisão pode variar devido ao método sample, utilizado no início, pois ele pega registros aleatórios, o que pode modificar o resultado final.
Nos próximos posts vamos explorar outros modelos e tentar melhorar esse score!
Nenhum comentário:
Postar um comentário